随着企业数字化转型的深入,微服务架构因其高内聚、低耦合、独立部署与弹性伸缩等优势,已成为现代软件系统设计的首选范式之一。在微服务架构下,数据设计与管理面临新的挑战与机遇。本文将快速解析微服务架构下的数据设计核心原则,并聚焦于数据处理服务的关键角色与实践方法。
一、微服务数据设计的核心原则
微服务架构强调每个服务拥有自己的私有数据库,即“数据库按服务拆分”(Database per Service)。这一原则避免了传统单体架构中数据库成为单点故障和性能瓶颈的问题,但也带来了数据一致性与事务管理的复杂性。因此,微服务数据设计的首要原则是:
- 领域驱动设计(DDD):通过界定限界上下文(Bounded Context),明确每个微服务的数据边界与职责,确保数据模型与服务业务逻辑高度内聚。
- 数据自治:每个微服务独立管理自身的数据存储(如SQL、NoSQL),对外仅通过定义良好的API暴露数据操作,隐藏内部实现细节。
- 最终一致性:在分布式环境下,强一致性难以保证,通常采用最终一致性模型,通过事件驱动、消息队列等方式异步同步数据。
二、数据处理服务的角色与定位
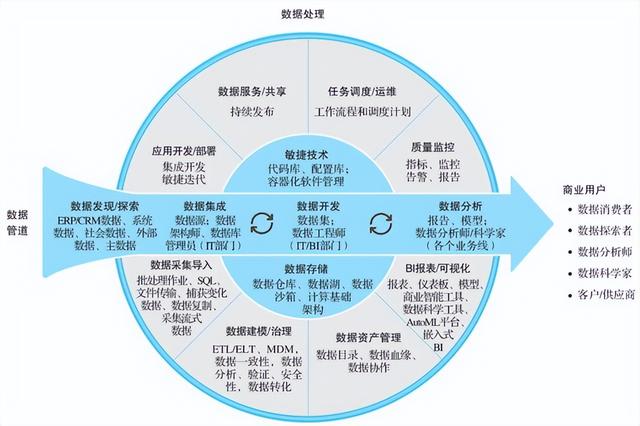
在微服务生态中,数据处理服务(Data Processing Service)扮演着至关重要的角色。它并非简单的CRUD服务,而是专注于数据的转换、聚合、清洗、分析与分发的专用服务。其主要职责包括:
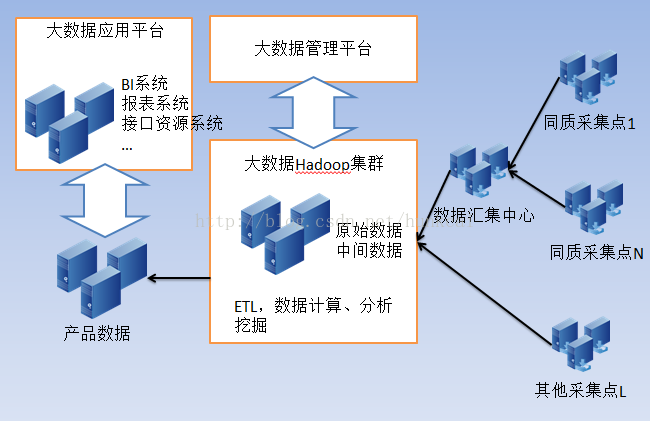
- 数据集成与同步:作为不同微服务间数据流动的桥梁,通过订阅领域事件(Domain Events),将数据从源服务同步到目标服务或数据仓库,确保数据在系统间的一致性视图。
- 实时数据处理:利用流处理技术(如Apache Kafka, Apache Flink)对事件流进行实时计算,生成业务指标、触发告警或更新衍生数据。
- 批量数据处理:处理历史数据或大数据量的ETL(提取、转换、加载)任务,支持离线分析与报表生成。
- 数据聚合与物化视图:为满足特定查询需求,将分散在多个服务中的数据聚合起来,构建物化视图(Materialized View),提升查询性能并减少跨服务调用。
三、数据处理服务的关键设计模式
- Saga模式:用于管理跨多个微服务的分布式事务。数据处理服务可作为Saga的协调者或参与者,通过一系列补偿性操作确保业务事务的最终一致性。
- CQRS(命令查询职责分离):将数据的写操作(命令)与读操作(查询)分离。数据处理服务常负责维护用于高效查询的读模型(Read Model),该模型通过订阅写模型(Write Model)的事件进行更新。
- 事件溯源(Event Sourcing):将系统状态的变化存储为一系列不可变的事件序列。数据处理服务可以消费这些事件流,重建当前状态或构建各种投影(Projection),为不同场景提供定制化的数据视图。
四、实践建议与挑战应对
- 技术选型:根据数据处理类型(实时/批量、吞吐量、延迟要求)选择合适的中间件,如Kafka用于事件流,Redis用于缓存,Elasticsearch用于搜索,数据湖/仓用于分析。
- 弹性与容错:设计数据处理服务时需考虑故障恢复、重试机制、死信队列等,确保数据不丢失且处理可恢复。
- 数据契约与演化:服务间通过事件或API共享数据时,需定义清晰的数据契约(如使用Avro、Protobuf Schema),并制定向后兼容的演化策略,避免因数据格式变更导致服务中断。
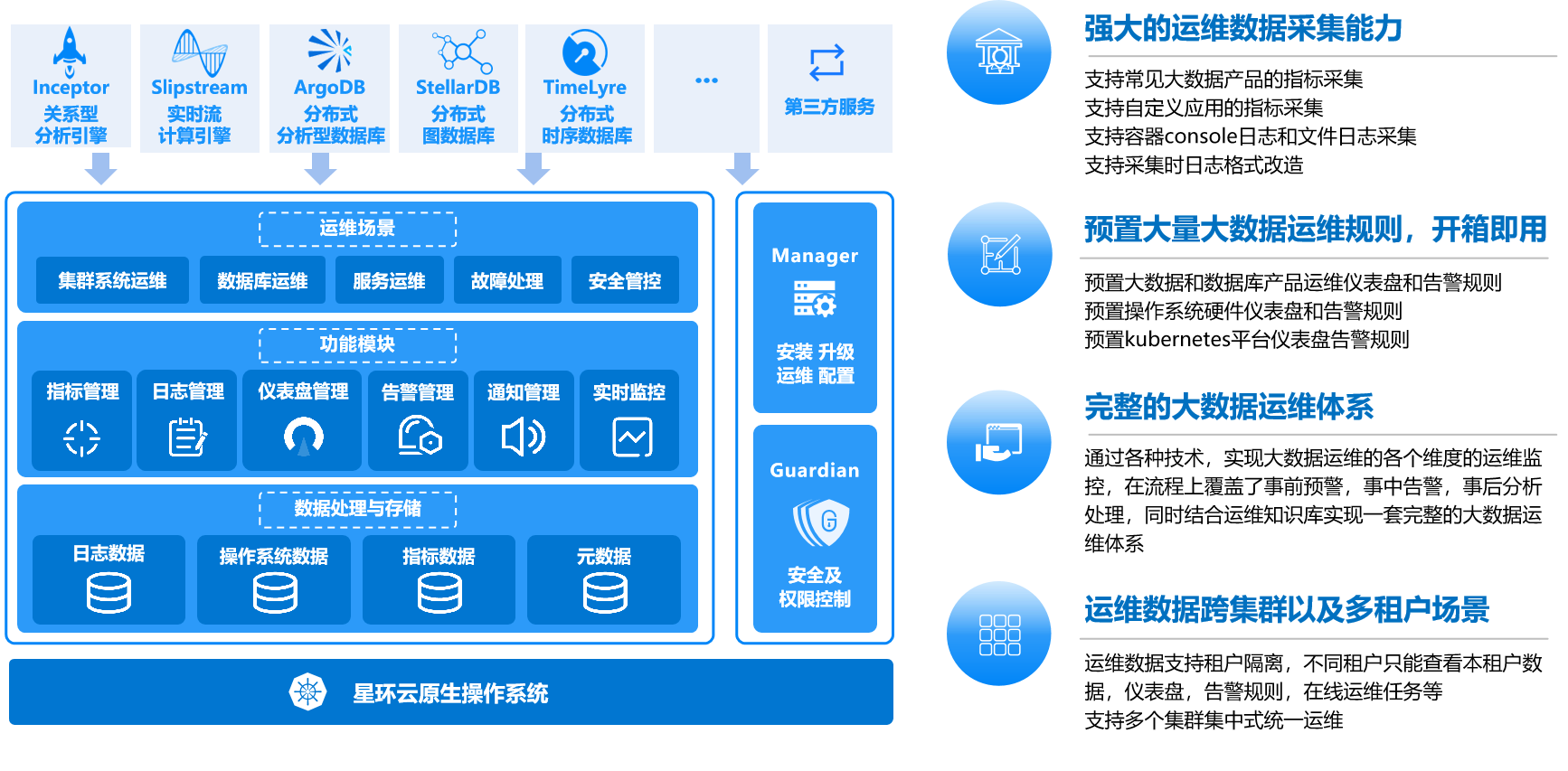
- 监控与可观测性:对数据处理流水线的吞吐量、延迟、错误率进行全方位监控,并建立端到端的追踪能力,以便快速定位数据不一致或处理滞后的根本原因。
五、
在微服务架构下,数据设计从“集中管控”转向“分布式自治”,数据处理服务则成为维系数据生态健康运转的核心组件。通过遵循领域驱动、事件驱动、最终一致性等原则,并合理运用Saga、CQRS、事件溯源等模式,可以构建出高弹性、可扩展且易于维护的数据处理体系。关键在于始终以业务价值为导向,在数据一致性、系统复杂度与开发运维成本之间找到最佳平衡点。