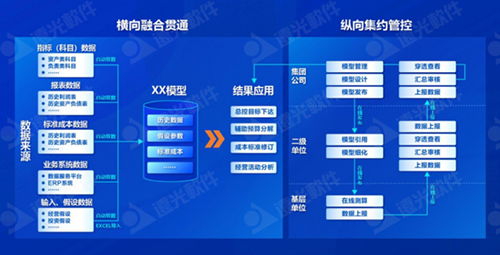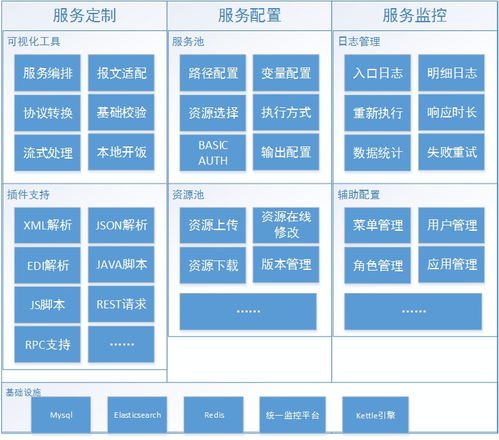
在数字化转型浪潮中,ETL(抽取-转换-加载)作为数据处理的核心环节,其功能复用已成为企业高效开发定制化服务的重要手段。本部分聚焦数据处理服务,探讨如何基于ETL能力构建灵活、可扩展的数据服务解决方案。
一、理解ETL数据处理功能的核心价值
ETL工具通常具备数据清洗、格式转换、规则校验等标准化处理能力。以金融行业为例,原始交易数据通过ETL去重、补全时间戳、转换币种后,可直接转化为合规报表。这些通用模块(如数据脱敏、聚合计算)可通过API封装为独立服务,避免重复开发。
二、构建数据处理服务的三大策略
- 模块化拆分:将ETL流程拆解为原子化处理单元(如地址标准化、异常检测),通过微服务架构暴露为RESTful接口。例如电商平台可将「用户行为数据清洗」模块复用至推荐系统和风控系统。
- 配置化驱动:开发可视化配置界面,允许业务人员通过拖拽方式组合数据处理流程。某物流企业通过配置字段映射规则,快速生成了不同国家的海关申报数据服务。
- 流水线编排:利用工作流引擎(如Apache Airflow)动态调度ETL任务链。当医疗科研需要整合多源患者数据时,可复用已有的「实验室数据解析」服务,仅需新增基因序列转换节点。
三、技术实现路径
- 服务化封装:使用Spring Boot等框架将ETL工具(如Talend、Kettle)的转换逻辑包装为gRPC或HTTP服务,支持异步处理和负载均衡。
- 元数据管理:建立数据处理能力目录,记录各服务的输入输出格式、性能指标和依赖关系,便于服务组合与优化。
- 资源隔离:通过Docker容器化部署,保障高优先级服务(如实时风控数据处理)的资源独占性。
四、实践案例与成效
某零售企业将商品ETL流水线中的「销售数据归一化」模块服务化后:
- 供应链系统调用该服务计算补货阈值,开发周期缩短60%
- 营销系统复用服务生成区域热力图,数据准备成本降低75%
- 通过服务版本管理,实现了新旧税率计算规则的无缝切换
五、演进方向
- 智能增强:集成机器学习模型,使数据处理服务具备自适应能力(如自动识别异常数据模式)
- 云原生升级:采用Serverless架构实现处理服务的按需扩缩容,进一步降低运维成本
通过将ETL的数据处理能力服务化,企业不仅能提升数据资产复用率,更可构建敏捷响应业务变化的定制化服务生态。关键在于平衡标准化与灵活性,让数据流水线成为创新业务的助推器而非瓶颈。