在数字化转型的浪潮中,数据中台已成为企业构建数据驱动能力的核心引擎。其中,数据处理服务作为数据中台的技术基石,承担着从原始数据到业务价值的转化重任。本方案旨在提供一个清晰、可扩展、高效的数据处理服务架构,以支撑企业级数据资产的沉淀与智能化应用。
一、数据处理服务的核心定位与目标
数据处理服务是数据中台的核心组件,负责数据的接入、清洗、加工、整合与服务化。其核心目标是实现 “数据即服务” ,通过标准化、模块化的处理流程,将异构、多源、海量的原始数据,转化为高质量、可复用、易理解的数据资产,并高效、稳定地供给上层数据分析、数据应用与智能决策系统。
二、总体技术架构设计
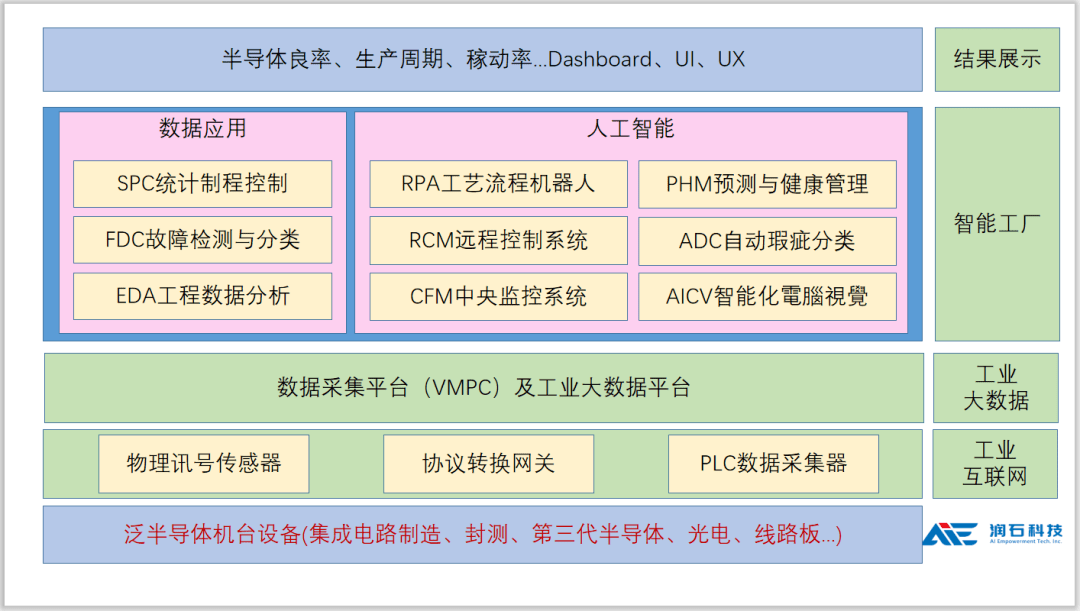
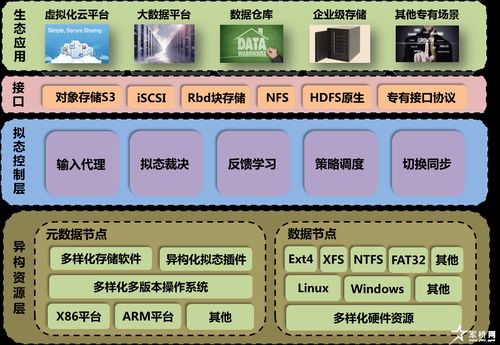
我们的数据处理服务采用分层、解耦的架构思想,构建一个 “采、存、算、管、用” 一体化的技术栈。整体架构自下而上可分为五层:
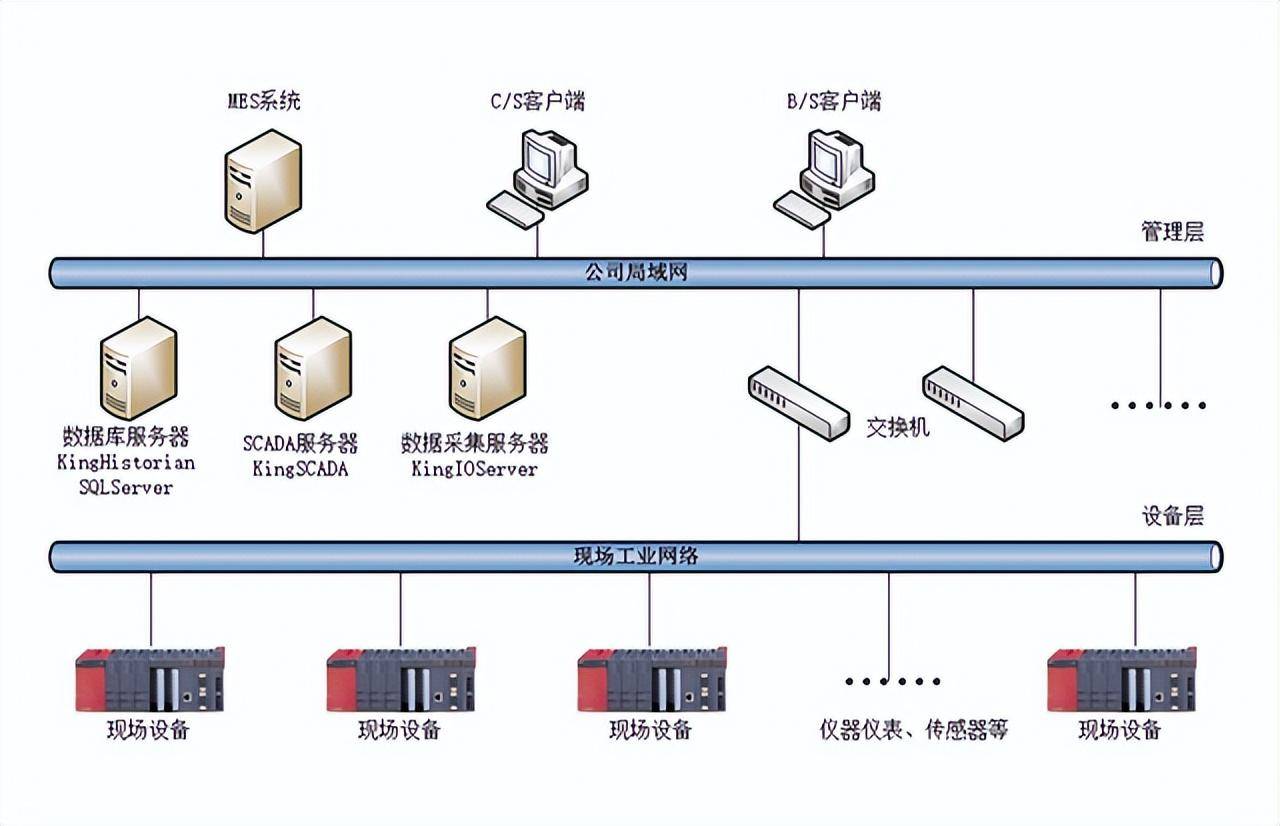
- 数据源与接入层:支持多模态数据接入,包括业务数据库(MySQL, Oracle)、日志文件、消息队列(Kafka)、物联网数据流及第三方API等。通过统一的数据接入网关,实现配置化、可视化的数据同步与实时采集。
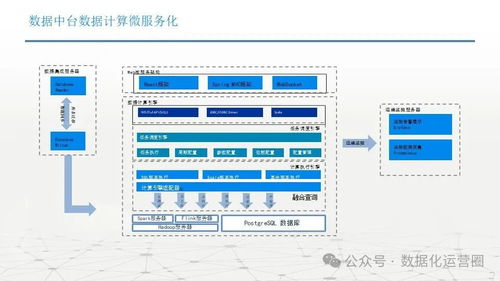
- 存储与计算层:构建混合存储体系,依据数据的热度、规模和访问模式,灵活选用对象存储(如OSS/S3)、数据湖(如HDFS)、MPP数仓(如ClickHouse, Greenplum)及实时数仓。计算引擎则融合批处理(Spark, Flink Batch)、流处理(Flink, Spark Streaming)与交互式查询(Presto, Impala),满足不同时效性与复杂度需求。
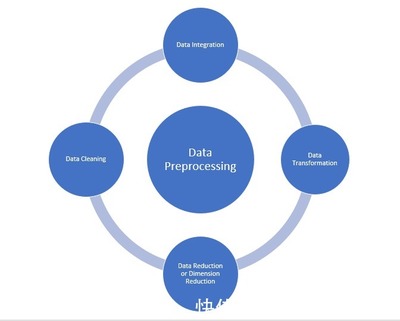
- 数据处理与加工层:这是服务的核心。我们设计了一套可视化数据开发平台,支持拖拽式任务编排。内置丰富的处理算子库,涵盖数据清洗(去重、标准化)、转换(关联、聚合)、质量校验与指标加工。通过统一调度系统(如DolphinScheduler, Airflow)实现任务依赖管理与自动化运维。
- 数据资产与管理层:建立企业级数据资产目录与元数据中心,对处理后的数据表、指标、API进行全生命周期管理。实施严格的数据血缘追踪与影响分析,保障数据质量与一致性。通过数据安全网关,实现列级权限控制、数据脱敏与访问审计。
- 数据服务与开放层:将加工后的数据资产封装成标准、统一的数据服务API,通过服务网关对外提供实时查询、批量数据推送、消息订阅等多种服务模式。支持微服务架构,便于业务系统灵活调用。
三、关键服务模块详解
- 统一数据集成服务:
- 批流一体集成:支持全量同步与增量实时捕获(基于CDC),降低对源系统的压力。
- 容错与监控:具备断点续传、脏数据隔离与实时监控告警能力。
- 智能数据开发与运维平台:
- 低代码开发:提供SQL、Python及可视化三种开发模式,降低技术门槛。
- 任务运维中心:提供任务监控、日志查看、性能诊断与智能告警的一站式运维体验。
- 数据质量管控服务:
- 规则引擎:内置完整性、准确性、一致性、时效性等校验规则库。
- 质量报告:自动生成数据质量评分与报告,驱动数据治理闭环。
- 数据服务治理平台:
- API全生命周期管理:涵盖设计、开发、测试、发布、上下线全过程。
- 流量治理:支持限流、熔断、降级等策略,保障服务高可用。
四、核心技术选型与优势
- 计算引擎:以 Apache Flink 为核心,实现真正的批流一体计算,保障低延迟与高吞吐。
- 数据湖仓:采用 Delta Lake / Iceberg 等开源数据湖表格式,在数据湖的灵活性上实现数仓的事务管理与性能优化。
- 资源调度:基于 Kubernetes 实现计算资源的弹性伸缩与混合部署,提升资源利用率。
- 优势:架构具有 云原生、高内聚低耦合、自主可控 的特点,能够快速响应业务变化,降低开发和运维成本。
五、实施路径与演进规划
建议采用“总体规划、分步实施、快速迭代”的策略:
- 一期(基础搭建,3-6个月):完成核心数据处理管道建设,接入1-2个关键业务域数据,产出首批核心数据指标与服务API。
- 二期(能力扩展,6-12个月):完善数据资产管理与数据质量体系,扩大数据接入范围,支撑更复杂的分析场景与初步的数据产品。
- 三期(价值深化,持续演进):强化数据服务的智能化能力,如基于机器学习的数据异常检测、自动归因分析,并探索数据驱动的业务创新模式。
###
本数据处理服务架构方案,致力于为企业打造一个健壮、敏捷、智能的数据生产与供给中心。通过标准化的流程与平台化的工具,我们将帮助组织打破数据孤岛,释放数据潜能,最终让数据成为业务增长与创新的核心驱动力。