随着大数据技术的不断演进,大数据处理体系结构已从传统的批处理模式向更加灵活、高效和智能化的方向发展。其中,“训练”(Training)与“微数据处理服务”(Micro Data Processing Services)作为两种关键的技术范式,正在深刻改变着数据处理的流程、效率和业务价值。本文将探讨这两种范式在大数据处理体系结构中的角色、特点及其协同作用。
一、大数据处理体系结构概览
一个典型的大数据处理体系结构通常包括数据采集、存储、处理、分析和应用等层次。传统架构(如Lambda架构)强调批处理与流处理的结合,而现代架构(如Kappa架构)则倾向于统一的流处理模型。无论哪种架构,核心目标都是高效、可靠地从海量数据中提取价值。在这一背景下,“训练”和“微数据处理服务”分别代表了数据处理的两个重要维度:模型构建与精细化实时处理。
二、训练(Training):数据驱动的模型构建
在大数据语境中,“训练”主要指利用大规模数据集构建和优化机器学习或人工智能模型的过程。这通常涉及以下关键环节:
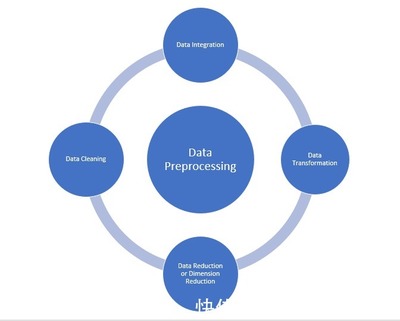
- 数据准备与特征工程:从原始数据中清洗、转换并提取有意义的特征,为模型训练提供高质量的输入。
- 模型选择与算法应用:根据业务问题(如分类、回归、聚类)选择合适的算法(如深度学习、随机森林),并在分布式计算框架(如Spark、TensorFlow)上进行训练。
- 迭代优化与验证:通过交叉验证、超参数调优等方法持续改进模型性能,确保其泛化能力。
训练过程往往依赖于批处理或离线计算,需要强大的计算资源(如GPU集群)和存储系统(如HDFS、云存储)。其输出——训练好的模型——是后续实时数据处理和智能应用的基础。
三、微数据处理服务(Micro Data Processing Services):精细化实时处理
“微数据处理服务”是一种基于微服务架构的数据处理模式,它将复杂的数据处理任务拆分为多个独立、可部署、可扩展的小型服务。每个服务专注于特定的数据处理功能(如数据过滤、聚合、转换或实时分析),并通过轻量级通信机制(如REST API、消息队列)协同工作。其主要特点包括:
- 实时性与低延迟:服务通常设计为流处理模式,能够对数据流进行即时响应,适用于监控、告警、个性化推荐等场景。
- 灵活性与可扩展性:每个服务可独立开发、部署和伸缩,便于团队协作和系统维护。容器化技术(如Docker、Kubernetes)进一步提升了其敏捷性。
- 精细化处理:服务专注于单一职责,例如一个服务专用于地理位置解析,另一个专用于用户行为评分,从而提高处理效率和可复用性。
微数据处理服务常与事件驱动架构结合,利用流处理引擎(如Flink、Kafka Streams)实现高效的数据流水线。
四、训练与微数据处理服务的协同
在实际的大数据处理体系结构中,训练与微数据处理服务并非孤立存在,而是紧密协作,共同支撑数据智能:
- 模型部署与实时推理:训练产生的模型可以封装为微服务(如通过TensorFlow Serving),集成到微数据处理流水线中,实现实时预测或决策(如欺诈检测、动态定价)。
- 反馈循环与持续学习:微数据处理服务产生的实时数据(如用户交互日志)可以反馈到训练系统,用于模型更新和再训练,形成闭环优化。
- 资源与架构统一:两者可共享底层基础设施(如云平台、容器编排),确保资源利用率和系统一致性。
五、实践挑战与未来展望
尽管训练与微数据处理服务带来了显著优势,但也面临挑战:训练需要高质量标注数据和算力成本;微服务则可能引入网络延迟和运维复杂度。未来趋势将更加注重:
- 自动化与智能化:AutoML等技术将简化训练流程;AI驱动的运维(AIOps)将提升微服务管理效率。
- 云原生与Serverless:基于云原生技术的数据处理服务将进一步降低部署门槛,实现按需伸缩。
- 边缘计算融合:训练与微处理将向边缘端延伸,满足物联网等场景的低延迟需求。
###
在大数据处理体系结构中,训练与微数据处理服务分别代表了“智能构建”与“敏捷执行”的双重能力。它们的有机结合,不仅提升了数据处理的效率和实时性,还推动了从数据到洞察、再到行动的快速转化。随着技术的不断发展,这一协同模式将继续深化,为企业数字化转型提供更强大的引擎。