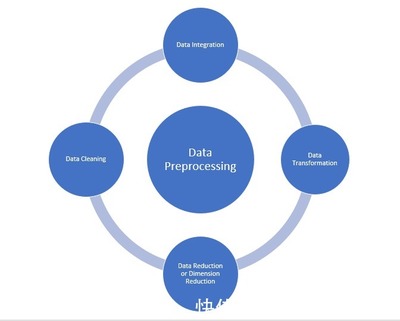
在当今数据驱动的时代,原始数据往往混杂着噪音、不一致与缺失,直接进行分析或建模如同在流沙上筑塔。数据清洗与预处理作为数据处理服务的核心前置环节,其质量直接决定了后续所有数据工作的成效与可信度。它并非简单的“打扫卫生”,而是一套系统化、专业化的关键步骤,旨在将原始数据转化为可靠、一致、可用于分析的高质量数据集。
关键步骤一:数据质量评估与问题诊断
一切清洗工作始于全面的“体检”。这一步需要对数据源进行探索性分析,识别存在的典型问题,包括:缺失值(如客户年龄字段为空)、异常值(如销售额出现负值)、不一致性(如日期格式混用“2023-12-01”和“12/01/2023”)、重复记录以及违反业务规则的无效数据(如邮政编码位数错误)。明确的诊断是制定精准清洗策略的前提。
关键步骤二:数据清洗的核心操作
基于诊断结果,实施具体的清洗操作:
- 处理缺失值:根据数据特性和业务场景,选择适当策略,如删除缺失率过高的记录、使用均值/中位数/众数进行填充,或采用更复杂的模型预测填充。
- 处理异常值:通过统计方法(如3σ原则)或业务规则识别异常点,并决定是修正、删除还是保留进行特殊分析。
- 规范格式与解决不一致:统一日期、数值、文本等格式;标准化分类数据(如将“男”、“M”、“男性”统一为“男”);解析和拆分复合字段。
- 去重与合并:识别并移除完全重复的记录,并处理近似重复(如同一客户因输入误差产生多条相似记录)。
- 错误修正与验证:依据业务逻辑或外部权威数据源,纠正明显的逻辑错误,并进行交叉验证。
关键步骤三:数据转换与集成
清洗后的数据需进一步“塑形”以满足分析需求:
- 数据转换:包括归一化或标准化以消除量纲影响,创建衍生特征(如从出生日期计算年龄),以及数据离散化(将连续年龄分段)。
- 数据集成:当数据来自多个源时,需解决实体识别(判断不同源的记录是否指向同一实体,如客户)和属性冗余问题,并将数据整合至统一视图。
关键步骤四:数据归约与交付
为提高处理效率并突出主要特征,可进行数据归约:
1. 维度归约:使用主成分分析(PCA)等方法减少不相关特征。
2. 数量归约:通过抽样技术,在保留数据分布特征的前提下减少数据量。
将处理完毕的干净、规整的数据集,以约定的格式(如CSV、数据库表、特定API接口)安全交付给下游的分析、建模或报表系统。
贯穿始终的环节:文档记录与自动化
专业的处理服务必须详细记录每一步清洗操作的规则、逻辑与参数,形成数据血缘,确保过程可追溯、可复现。对于常规化任务,应构建自动化清洗流水线或脚本,以提升效率、减少人为错误并保证处理标准的一致性。
数据清洗与预处理是一项需要严谨态度、业务知识和技术能力相结合的工作。一个优秀的数据处理服务,正是通过这些细致且关键步骤,将混沌的原始数据转化为清晰、可靠的“高质量燃料”,从而为企业的精准决策、智能模型和深度洞察提供坚实可信的基础。忽视这一过程,任何高级的数据分析与人工智能应用都将是空中楼阁。